摘要:具體的數(shù)據(jù)預(yù)處理涉及重復(fù)值、異常值/缺失值/極端值、標準化和數(shù)據(jù)頻率的處理。duplicated(subset=[key1,key2,duplicated(subset=[key1,key2,對數(shù)據(jù)范圍內(nèi)的所有因子做出如下調(diào)整:該方法不足在于,量化領(lǐng)域常用的數(shù)據(jù)如股票價格、token價格常呈現(xiàn)尖峰厚尾分布,并不符合正態(tài)分布的假設(shè),在該情況下采用方法將有大量數(shù)據(jù)錯誤地被識別為異常值。...
前言
書接上回,我們發(fā)布了《用多因子策略構(gòu)建強大的加密資產(chǎn)投資組合》系列文章的第一篇 - 理論基礎(chǔ)篇,本篇是第二篇 - 數(shù)據(jù)預(yù)處理篇。
在計算因子數(shù)據(jù)前/后,以及測試單因子的有效性之前,都需要對相關(guān)數(shù)據(jù)進行處理。具體的數(shù)據(jù)預(yù)處理涉及重復(fù)值、異常值/缺失值/極端值、標準化和數(shù)據(jù)頻率的處理。
一、重復(fù)值
數(shù)據(jù)相關(guān)定義:
- 鍵(Key):表示一個獨一無二的索引。eg. 對于一份有全部token所有日期的數(shù)據(jù),鍵是“token_id/contract_address - 日期”
- 值(Value):被鍵索引的對象就稱之為“值”。
診斷重復(fù)值的首先需要理解數(shù)據(jù)“應(yīng)當”是什么樣子。通常數(shù)據(jù)的形式有:
- 時間序列數(shù)據(jù)(Time Series)。鍵是“時間”。eg.單個token5年的價格數(shù)據(jù)
- 橫截面數(shù)據(jù)(Cross Section)。鍵是“個體”。eg.2023.11.01當日crypto市場所有token的價格數(shù)據(jù)
- 面板數(shù)據(jù)(Panel)。鍵是“個體-時間”的組合。eg.從2019.01.01-2023.11.01 四年所有token的價格數(shù)據(jù)。
原則:確定了數(shù)據(jù)的索引(鍵),就能知道數(shù)據(jù)應(yīng)該在什么層面沒有重復(fù)值。
檢查方式:
- pd.DataFrame.duplicated(subset=[key1, key2, ...])
- 檢查重復(fù)值的數(shù)量:pd.DataFrame.duplicated(subset=[key1, key2, ...]).sum
- 抽樣看重復(fù)的樣本:df[df.duplicated(subset=[...])].sample找到樣本后,再用df.loc選出該索引對應(yīng)的全部重復(fù)樣本
- pd.merge(df1, df2, on=[key1, key2, ...], indicator=True, validate='1:1')
- 在橫向合并的函數(shù)中,加入indicator參數(shù),會生成_merge字段,對其使用dfm['_merge'].value_counts可以檢查合并后不同來源的樣本數(shù)量
- 加入validate參數(shù),可以檢驗合并的數(shù)據(jù)集中索引是否如預(yù)期一般(1 to 1、1 to many或many to many,其中最后一種情況其實等于不需要驗證)。如果與預(yù)期不符,合并過程會報錯并中止執(zhí)行。
二、異常值/缺失值/極端值
產(chǎn)生異常值的常見原因:
- 極端情況。比如token價格0.000001$或市值僅50萬美元的token,隨便變動一點,就會有數(shù)十倍的回報率。
- 數(shù)據(jù)特性。比如token價格數(shù)據(jù)從2020年1月1日開始下載,那么自然無法計算出2020年1月1日的回報率數(shù)據(jù),因為沒有前一日的收盤價。
- 數(shù)據(jù)錯誤。數(shù)據(jù)提供商難免會犯錯,比如將12元每token記錄成1.2元每token。
針對異常值和缺失值處理原則:
- 刪除。對于無法合理更正或修正的異常值,可以考慮刪除。
- 替換。通常用于對極端值的處理,比如縮尾(Winsorizing)或取對數(shù)(不常用)。
- 填充。對于缺失值也可以考慮以合理的方式填充,常見的方式包括均值(或移動平均)、插值(Interpolation)、填0df.fillna(0)、向前df.fillna('ffill')/向后填充df.fillna('bfill')等,要考慮填充所依賴的假設(shè)是否合。
- 機器學習慎用向后填充,有 Look-ahead bias 的風險
針對極端值的處理方法:
1.百分位法。
通過將順序從小到大排列,將超過最小和最大比例的數(shù)據(jù)替換為臨界的數(shù)據(jù)。對于歷史數(shù)據(jù)較豐富的數(shù)據(jù),該方法相對粗略,不太適用,強行刪除固定比例的數(shù)據(jù)可能造成一定比例的損失。
2.3σ / 三倍標準差法
標準差 體現(xiàn)因子數(shù)據(jù)分布的離散程度,即波動性。利用 范圍識別并替換數(shù)據(jù)集中的異常值,約有99.73% 的數(shù)據(jù)落入該范圍。該方法適用前提:因子數(shù)據(jù)必須服從正態(tài)分布,即 。
其中,, ,因子值的合理范圍是。
對數(shù)據(jù)范圍內(nèi)的所有因子做出如下調(diào)整:
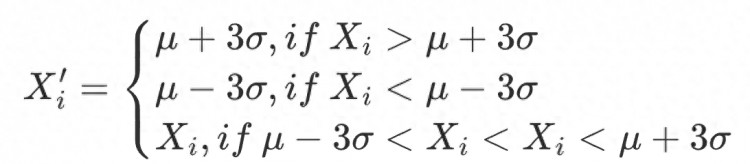
該方法不足在于,量化領(lǐng)域常用的數(shù)據(jù)如股票價格、token價格常呈現(xiàn)尖峰厚尾分布,并不符合正態(tài)分布的假設(shè),在該情況下采用方法將有大量數(shù)據(jù)錯誤地被識別為異常值。
3.絕對值差中位數(shù)法(Median Absolute Deviation, MAD)
該方法基于中位數(shù)和絕對偏差,使處理后的數(shù)據(jù)對極端值或異常值沒那么敏感。比基于均值和標準差的方法更穩(wěn)健。
絕對偏差值的中位數(shù)
因子值的合理范圍是。對數(shù)據(jù)范圍內(nèi)的所有因子做出如下調(diào)整:

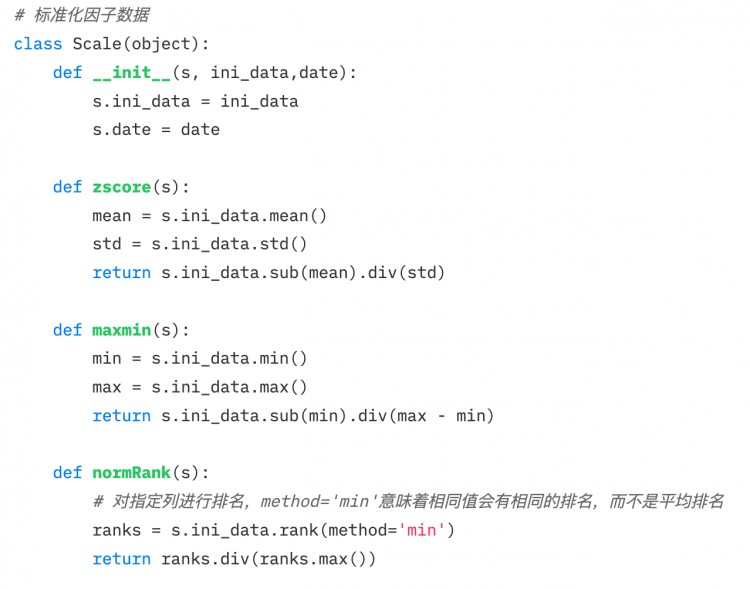
三、標準化
1.Z-score標準化
- 前提:
- 由于使用了標準差,該方法對于數(shù)據(jù)中的異常值較為敏感
2.最大最小值差標準化(Min-Max Scaling)
將每個因子數(shù)據(jù)轉(zhuǎn)化為在 區(qū)間的數(shù)據(jù),以便比較不同規(guī)模或范圍的數(shù)據(jù),但它并不改變數(shù)據(jù)內(nèi)部的分布,也不會使總和變?yōu)?。
- 由于考慮極大極小值,對異常值敏感
- 統(tǒng)一量綱,利于比較不同維度的數(shù)據(jù)。
3.排序百分位(Rank Scaling)
將數(shù)據(jù)特征轉(zhuǎn)換為它們的排名,并將這些排名轉(zhuǎn)換為介于0和1之間的分數(shù),通常是它們在數(shù)據(jù)集中的百分位數(shù)。*
- 由于排名不受異常值影響,該方法對異常值不敏感。
- 不保持數(shù)據(jù)中各點之間的絕對距離,而是轉(zhuǎn)換為相對排名。
其中,, 為區(qū)間內(nèi)數(shù)據(jù)點的總個數(shù)。
四、數(shù)據(jù)頻率
有時獲得的數(shù)據(jù)并非我們分析所需要的頻率。比如分析的層次為月度,原始數(shù)據(jù)的頻率為日度,此時就需要用到“下采樣”,即聚合數(shù)據(jù)為月度。
下采樣
指的是將一個集合里的數(shù)據(jù)聚合為一行數(shù)據(jù),比如日度數(shù)據(jù)聚合為月度。此時需要考慮每個被聚合的指標的特性,通常的操作有:
- 第一個值/最后一個值
- 均值/中位數(shù)
- 標準差
上采樣
指的是將一行數(shù)據(jù)的數(shù)據(jù)拆分為多行數(shù)據(jù),比如年度數(shù)據(jù)用在月度分析上。這種情況一般就是簡單重復(fù)即可,有時需要將年度數(shù)據(jù)按比例歸集于各個月份。